This is where it all starts. Writing systems are the most visual part of linguistics, and their beauty is what draws many linguistics geeks to neography. Writing systems are fascinating on their own, but knowing all the different types opens new doors for neographers.
For brief definitions, see the terminology page.
Contents
1. Segmental
Alphabet
Cipher
Abjad
2. Syllabic
Syllabary
Abugida
3. Segmental-Syllabic
Alphasyllabary
Semi-Syllabary
Alphabetic Syllabary
4. Logographic
Logography
Logosyllabary
5. Other
Mixed Systems
Shorthand
Featural Scripts
Writing systems can be categorized broadly as two types: phonetic scripts that represent the sounds of spoken language, and ideographic scripts that represent ideas. Phonetic scripts can be further categorized as segmental or syllabic.
Here is a quick visual explanation of how these different scripts work, and how they might be used to represent an English sentence. We’ll describe these systems one-by-one and look at examples.


Consonants
Characters for sounds produced by varying constrictions of the vocal tract.

Vowels
Characters for high-sonority sounds. Usually the core of a syllable.

Syllabograms
Characters that represent at least one consonant and one vowel. Commonly one consonant then one vowel.

Logograms
Characters that represent words or word segments. Writing is compact, but has more complex and numerous characters.

Pictograms
Symbols that represent ideas, concepts, or messages, but aren’t part of language. Includes icons, signage, and more.
1. Segmental
Segmental writing systems use the smallest recognizable units of speech as building blocks: letters, which can be consonants or vowels.
Alphabet
Alphabets are straightforward systems: each unique sound has a unique symbol, and these symbols are arranged in an order that matches the temporal sequence in which they’re spoken.
English is one of many languages in or from Europe that uses an alphabet based on Latin script, also known as the Roman alphabet. Some languages add or remove a few letters, such as ⟨ð⟩ and ⟨þ⟩ in Icelandic or ⟨ß⟩ in German, but generally it’s more or less the same set of letters.
Το ελληνικό αλφάβητο είναι το αλφαβητικό σύστημα γραφής που χρησιμοποιείται για τη γραφή της ελληνικής γλώσσας, από τον 8ο αιώνα π.Χ.
Кириллические алфавиты: система письменности и алфавит для какого-либо иного языка, основанные на этой старославянской кириллице.
There’s a lot of diversity in the Roman alphabet’s usage in different languages, but there are entirely different alphabets out there. Greek and Cyrillic, the latter used for Russian and other slavic languages, look very different, but they also have a few similar letters due to historical relationships with Roman. All three alphabets have letters and sounds with no counterparts in the others.
Other alphabetic scripts in use today include Armenian and Georgian:
Հայերենի այբուբեն կամ Հայոց գրեր, հայերենի հնչյունաբանական գրերի համակարգը, որը ստեղծվել է Մեսրոպ Մաշտոցի կողմից հայերենի համար։
ქართული დამწერლობა, რომელსაც იყენებს ქართული ენა და მისი მონათესავე ქართველური ენები, ასევე სხვა კავკასიური ენებიც.
Orthography
The description of alphabets as simply as one letter for one sound is unfortunately only a theoretical ideal. Reality is much messier. Many languages have orthography: a system of spelling rules that frequently conflicts with how the letters are supposed to be pronounced. This is usually because spelling rules are standardized at some point in history and remained unchanged despite the language changing gradually over time. Tibetan is an extreme example: its spelling still reflects the spoken language from the 9th century!
Many languages use the same Roman alphabet letters to represent a variety of different sounds, often many more sounds than there are letters. To do more with a limited palette, many languages use digraphs and diacritics.
Digraphs are pairs of letters that are read as a single unit to produce unique sounds, like ⟨th, sh, ch, ng⟩. Some are redundant with sounds made by individual letters, like ⟨ph, gh, ck, ks, wh, qu⟩. The redundant digraphs are responsible for many silent letters and are usually relics of historical spelling or words borrowed from other languages. A few trigraphs exist too, like ⟨sch, tch⟩. Some digraphs are used only for rendering sounds from other languages or scripts, such as ⟨zh, kh, dh⟩ for ⟨ж, х, ð⟩.
Diacritics are markings above, below, or sometimes through a letter that distinguish its pronunciation or use. English sometimes uses diacritics in loanwords borrowed from other languages. For example, the acute accents in résumé indicate how it’s pronounced, while the dieresis in naïve indicates that the consecutive vowels are pronounced separately. Vietnamese is one of the more extreme examples of this:
Tiếng Việt là ngôn ngữ của người Việt và là ngôn ngữ chính thức tại Việt Nam.
Cipher
Different alphabets usually have different numbers of letters depending on how many sounds are in the language they were created for. They’re not simply ‘reskinned’ versions of each other with 1‑to‑1 matching characters and sounds; that would be a cipher.
A simple Caesar cipher reshuffles the letters of the alphabet, such as by using the letter that comes next in the alphabet to replace every letter. Thus the quick brown fox becomes uif rvjdl cspxo gpy. Cipher rings—where two rings of the alphabet can be rotated relative to each other—are tools to encrypt and decrypt basic ciphers. In the example image, cipher becomes vbiaxk.

This is the simplest possible cipher; imagine also rotating the cipher ring for each new letter encrypted, and then adding a complicated pattern of how to turn the ring. Imagine adding additional rings, where each one determines how to rotate the next. Encryption can apply extremely complicated mathematical rules and be unfeasible to decrypt even with a supercomputer.
Ciphers are not a type of writing system per se, more of a tool for cryptography, but they do demonstrate the arbitrary relationship between symbol and sound. Ciphers don’t just have to replace letters with other letters: it could be numbers, pictograms, dots, new symbols, multiple symbols, or anything really. Whenever you see a fictional fantasy or sci‑fi alphabet with 26 letters corresponding exactly to the English alphabet, it’s more of a cipher than a new alphabet.
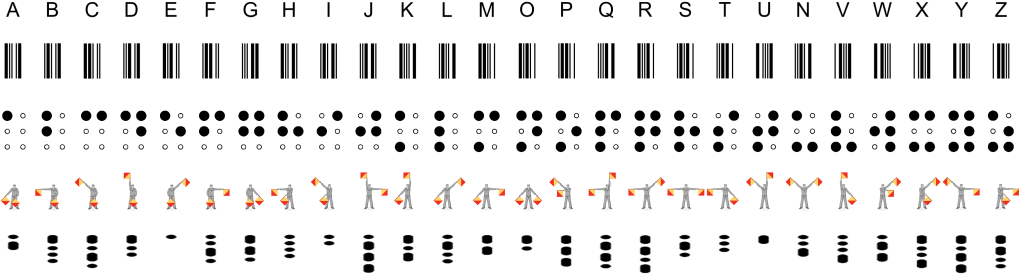
Ciphers can also be used to extend the usability of an existing alphabet, adapting it to different media. These are generally human-readable, but not always. For example:
- Barcodes make the alphabet machine-readable.
- Braille makes the Roman alphabet accessible through a tactile medium.
- Flag semaphore makes the alphabet readable at a physical distance.
- Morse code renders the alphabet through a binary, on-or-off electrical or radio signal.
Abjad
An abjad is a kind of alphabet that contains only consonants, leaving vowels to be filled in by the reader’s intuition. This might sound difficult and ambiguous, but it seems more reasonable if you can read the phrase th qck brwn fx jmps vr th lz dg. It’s surprisingly clear, and conveniently compact!
עִבְרִית היא שפה שמית, ממשפחת השפות האפרו-אסיאתיות, הידועה כשפתם של היהודים ושל השומרונים.
Languages that use abjads, however—notably Arabic and Hebrew—don’t just omit vowels for brevity. In these languages, the vowels in a word often change based on different grammatical uses of a word, so the consonants better represent the ‘root’ that distinguishes a word.
الأبجدية العربية هي الأبجدية التي تستخدم الحروف العربية في الكتابة؛ وتعد حاليًا أكثر نظام كتابة استخدامًا بعد الألفبائية اللاتينية.الفبای عربی یا ابجدی عربی حروف نوشتاری خط و زبان عربی است.
The word abjad is formed from the first four letters of the Arabic alphabet, similar to how alphabet is made from the names of the first two Greek letters. Both Arabic and Hebrew are written from right-to-left, and Arabic has the interesting feature of letters within words being joined together, with four different forms of each letter for the beginning, middle, and end of a word, or isolated from a word.
2. Syllabic
Syllabic writing systems use whole syllable units as building blocks.
Syllabary
A syllabary is similar to an alphabet, but the characters represent whole syllables. Each syllabic character includes at least one consonant sound and one vowel sound; in most cases it’s one consonant followed by one vowel.
Syllabaries generally have more symbols than alphabets due to their multiplicative nature. English has five vowels and twenty-one consonants: to make a consonant-vowel (CV) syllabary out of that, they’d multiply to produce 105 characters. Making every consonant-vowel-consonant (CVC) combination would produce 2205 characters!
To avoid large, unwieldy syllabaries, one solution is to add an echo vowel or omit the terminal consonant, so cat might be written as ca-ta or just ca. Also, rare letter combinations can be omitted, and languages with syllabaries tend to have well-suited, simple syllable structures, usually no more complex than CVC. English is therefore poorly suited to be written with a syllabary.
| – | k | s | t | n | h | m | y | r | w | |
| a | あア | かカ | さサ | たタ | なナ | はハ | まマ | やヤ | らラ | わワ |
| i | いイ | きキ | しシ | ちチ | にニ | ひヒ | みミ | りリ | ゐヰ | |
| u | うウ | くク | すス | つツ | ぬヌ | ふフ | むム | ゆユ | るル | |
| e | えエ | けケ | せセ | てテ | ねネ | へヘ | めメ | れレ | ゑヱ | |
| o | おオ | こコ | そソ | とト | のノ | ほホ | もモ | よヨ | ろロ | をヲ |
Japanese has a particularly complicated mixture of writing systems that includes not one but two syllabaries collectively called kana, which both encompass the same set of consonant-vowel pairs. This duplicity of symbols might seem strange, but remember that the Roman, Greek, and Cyrillic alphabets also come in two different sets—uppercase and lowercase—and that each has a variety of notational and expressive uses. Similarly, Hiragana (shown first in each table cell) is used for native Japanese words, and Katakana is used for loanwords of foreign origin, often English.
Abugida
Abugidas, common in South and Southeast Asia, are a type of syllabary that features visual similarity between characters for similar sounds, whereas syllabaries have no visual-audible correlation. In Devanagari, ke, ka, ko are respectively के, का, को. As you might have guessed, the word abugida originates from the same pattern as alphabet and abjad.
देवनागरी एक भारतीय लिपि है जिसमें अनेक भारतीय भाषाएँ तथा कई विदेशी भाषाएँ लिखी जाती हैं। यह बायें से दायें लिखी जाती है। इसकी पहचान एक क्षैतिज रेखा से है जिसे ‘शिरोरेखा’ कहते हैं।
Canadian Aboriginal Syllabics is an abugida where the vowel is not determined by a diacritic but by the orientation of the character. There are four vowels, indicated by the character being upright or rotated 90°, 180°, or 270°. Note that CAS was invented in the 19th century and didn’t evolve naturally, so it’s considered a constructed script.
ᑎᑎᕋᐅᓯᖅᑐᖅ ᓄᑖᖅ—ᐊᑲᐃᓗᑕᖅ ᐃᓄᒃᑎᑐᑦ ᓇᐃᒡᓕᒋᐊᖅᓯᒪᔪᖅ ᑎᑎᖅᑲᖅ. ᓱᓕᐊᖅ ᐂᒌᒧᒦᓇ ᐱᖅ ᓱᓕᐊᖅ ᐊᔪᕿᖅᑐᐃᔨ ᑭᒡᒐᖅ ᐃᑦᓴᖅ.
3. Segmental-Syllabic
Segmental-syllabic writing systems have overlapping or blended qualities of segmental systems and syllabic systems.
Alphasyllabary
The term alphasyllabary does not have a universally agreed upon meaning. Many use it as an outdated or synonymous term for abugida. For our purposes, we’re using the term to refer to a distinct type of writing system as defined by Bright and Daniels.
Alphasyllabaries are an intermediate between abjads and abugidas. Like abjads, the primary characters represent consonants. And like abugidas, secondary symbols like diacritics represent vowels. Alphasyllabaries are different from abjads in that vowel diacritics are mandatory, and they differ from abugidas in that consonants do not have an ‘inherent vowel’ in the absence of a diacritic.

Arabic and Hebrew can both be written with full vowel indication by adding harakat and niqqud diacritics to them respectively. This is done in for purposes like teaching non-native speakers or for religious scripture. When vowels are indicated this way, they functionally become alphasyllabaries rather than abjads.
Semi-Syllabary
A semi-syllabary is a writing system that includes both syllabograms and alphabetic characters. It’s sort of like an alphabet-syllabary chimaera.
As exotic as this seems, you might have used it before—using the names of letters and numbers as de facto syllables—in text messages like: “Can I C U B4 2morrow? Th@ would B gr8.”
日本語の表記体系(にほんごのひょうきたいけい)では、日本語の文章等を文字によって表記するための系統的な方法について解説する。
Although Japanese hiragana and katakana are usually considered syllabaries, they can also be described as semi-syllabaries. For one thing, there are single-phoneme glyphs for the five vowels and the consonant /n/ when it comes at the end of a syllable. That on its own qualifies it as a semi-syllabary, albeit an imbalanced one with many more syllabograms than letters. But furthermore, consonant-vowel combinations that lack a dedicated syllabogram can be spelled using one syllabogram as a consonant and another as a vowel. For example, the kanji cha ⟨茶⟩ is transcribed into hiragana as chi‑ya ⟨ちゃ⟩, meaning both are functioning like alphabetic letters.
Alphabetic Syllabary
Alphabetic syllabaries are another kind of writing system that blend alphabet and syllabary in different way. The main units in this type of writing are syllables, however they are assembled from alphabetic elements arranged into discrete syllable units.
Hangul, the writing system used to write Korean, is the most widely used alphabetic syllabary.
한글은 홀소리와 닿소리 모두 소리틀을 본떠 만든 음소문자로 한글 맞춤법에서는 닿소리 14개과 홀소리 10개, 모두 24개를 표준으로 삼는다.
Letters are distinguished as the initials (I), medials (M), and finals (F) of a syllable. Letters are placed in syllable blocks by whether the vowel is more vertical or horizontal in shape, with up to two medials and finals each, though two finals are uncommon. Here’s how alphabetic elements are blocked into syllable units:

There are up to 11,172 possible syllables, but in practice 99.9% of Korean writing uses just 512, with half that number making up 88.2% of all writing.
4. Logographic
Logographic writing systems represent meanings rather than sounds.
Logography
Logograms are a completely different way to write linguistic information. Instead of representing spoken sounds, each character represents a word, idea, or morpheme: a meaningful word segment such as ⟨-s⟩ for pluralization or ⟨-ation⟩ for a process or phenomenon.
These are common among the oldest writing systems in history. Some well-known logographic scripts include Chinese characters, ancient Egyptian hieroglyphs, and ancient cuneiform.
中文書面語,又稱通用中文,是用來表述中文漢語的書寫系統,主要使用漢字記錄,力求會通南北。
This separation of spoken words and written words has the advantage of being understandable regardless of dialect or even language. Japan, Vietnam, and Korea formerly used the Chinese writing system despite speaking different languages. The downside, though, is the high barrier of entry: it’s like learning a new language in and of itself.

There are several types of logographic characters, and a logographic script might use several or all of them:
- Pictograms
Pictures of what they represent, as the name suggests, although somewhat usually simplified and stylized. Examples in Chinese include tree ⟨木⟩, mountain ⟨山⟩, and woman ⟨女⟩.
- Simple ideograms
Icons that represent abstract ideas, or that represent physical things in an abstract way. These can be derived from pictorial glyphs. For example, root ⟨本⟩ and apex ⟨末⟩ are formed by marking the bottom and top of the tree glyph.
- Compound ideograms
Glyphs assembled from two or more pictographic or ideographic characters that together suggest the meaning of the combined glyph. For example, tree ⟨木⟩ can be combined with a leaning man to make shade or rest ⟨休⟩ or tripled to make forest ⟨森⟩.
- Rebus compounds
Glyphs repurposed for homophones or near-homophones. It’s like if you didn’t have a character for son, so you used the one for sun instead and it eventually became standard. The original word might even need to be modified to distinguish it from the new word associated with the glyph.
- Phono-semantic compounds
Glyphs assembled from two characters: a rebus-like phonetic component that suggests the pronunciation and a semantic component that suggests the meaning. About 90% of Chinese characters are of this category.
Logosyllabary
A logosyllabary is a partially phonetic and partially logographic script. Logograms can be used for their phonetic values to represent syllables.
You might have wondered: If a logography represents words semantically instead of phonetically, how do they write foreign names or new words that don’t have a symbol? No natural logographic writing system is actually purely logographic; they all have some degree of phonetic notation.
Logograms can represent new words by acting like a syllabary. Words, particularly one-syllable words, can be used like the letters of a syllabary. Scripts that do this, such as Chinese, may thus be described as logosyllabic. Many syllabaries evolved from logographies in this manner.
5. Other
Other writing systems defy the categories above.
Mixed Systems
Alphabets (including abjads), syllabaries (including abugidas), and logograms are three convenient categories to describe most writing systems. Reality, though, is rarely as neat and clean as theory, and the writing systems that have arisen over history tend to be as messy as they are rich and diverse.

As we’ve already seen, abugidas blend the boundary between alphabet and syllabary, and logosyllabic scripts do likewise for syllabaries and logograms. Writing systems can be impure: alphabets with syllable letters, abjads with a vowel or two, and so on.
Few writings systems are pure: Chinese uses logograms as syllables, Arabic has a small number of vowels, and even English has single letters that represent multiple consonant sounds; ⟨j, q, x⟩ are respectively /dʒ, kw, ks/ in IPA. Ancient Egyptian varies over the course of its history but used all three together at times.
Japanese has one of the most complicated modern writing systems. It includes the two syllabary sets mentioned earlier, which themselves contain alphabetic letters for the vowels and /n/ consonant; kanji, a logographic script closely related to Chinese; Romaji, the Roman alphabet used for some purposes; Arabic numerals; and additional mechanisms in limited degrees.
Even English occasionally uses symbols that can be considered logograms: and ⟨&⟩, number ⟨#⟩, dollar ⟨$⟩, percent ⟨%⟩, section ⟨§⟩, degree ⟨°⟩, mathematical symbols ⟨+,-,×,÷,=⟩, unit abbreviations ⟨kg,cm,ft,in⟩, and so on.
Shorthand
Shorthand is a method of writing significantly faster or more condensed than regular longhand writing. The process of writing shorthand is called stenography, and often could be done at the same speed as spoken speech. It was more widely used in the early 20th century by secretaries, journalists, and police, but has been overtaken by recording and dictation devices.
Like ciphers, shorthand is not exactly a type of writing system on its own, more like a technique of encoding an existing writing system. It often combines aspects of segmental, syllabic, and logographic writing systems. Many forms of shorthand therefore function like a mixed writing system. Here’s an example of Gregg shorthand:
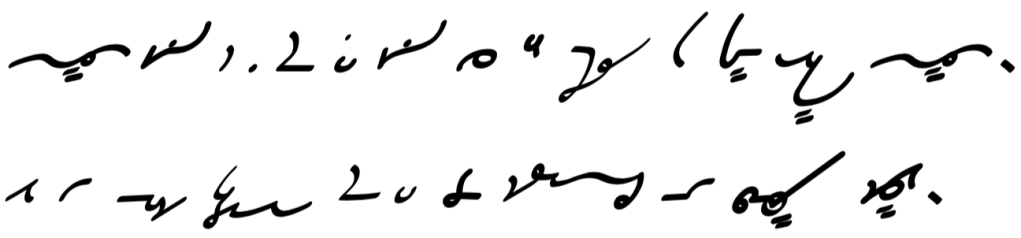
The letters themselves are often straight lines and loose curves that can be written in quick movements.
Abbreviations are often used instead of writing common words or phrases in full. For example, in Gregg shorthand, the words please and can can be written as just pl and k. In this way, they function as logograms despite being derived from (and used alongside) alphabetic letters. Shorthand systems also use many unique glyphs for common words, such as ⟨∴⟩ for therefore and ⟨∵⟩ for because.
Featural Scripts
There isn’t universal consensus on what it means for a script to be featural. It can be used as either a descriptor or a category.
Some define featural writing systems as scripts in which the glyphs are assembled from sub-glyphs that represent features, such as place and manner of articulation, voicing, length, and so on.
Featuralism can also be understood as a property that can apply to a script in degrees.
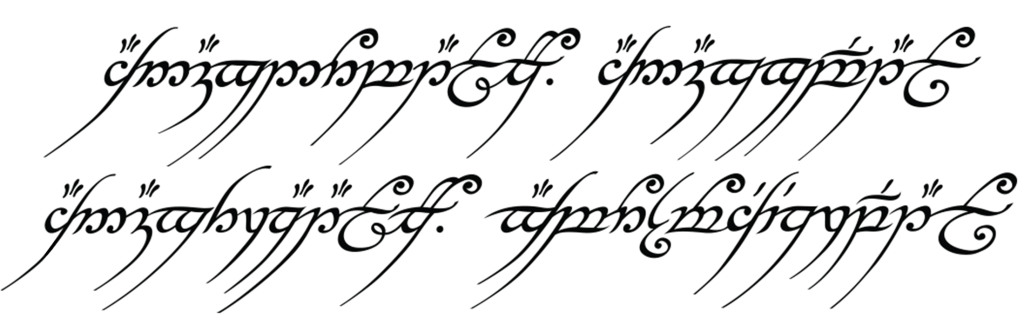
Tengwar, the fictional script for Tolkien’s Elvish languages, is an alphasyllabary with lots of featuralism. About two thirds of its consonants follow clear visual patterns:
| Plosive | Fricative | Sibilant | Nasal | ||||
| Labial | 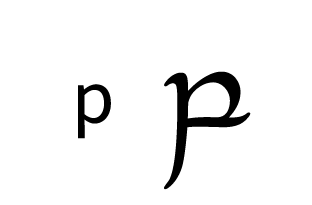 | 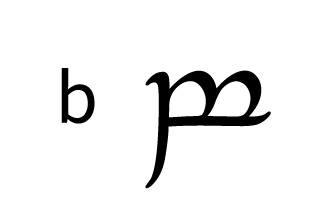 | 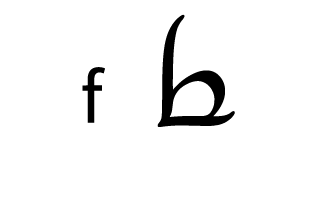 | 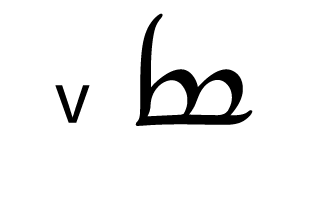 | 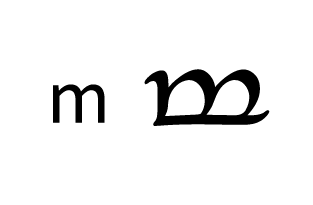 | ||
| Coronal/ Palatal | 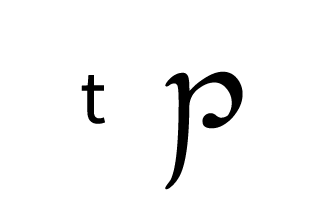 | 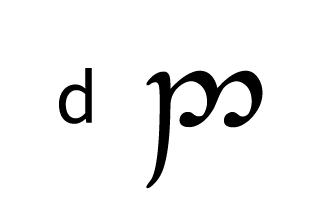 | 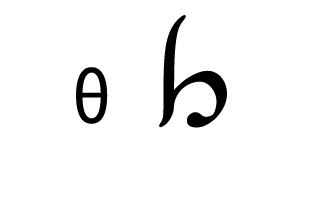 | 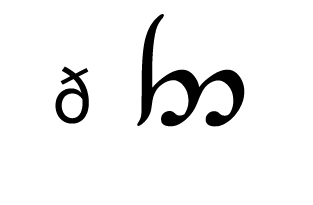 | 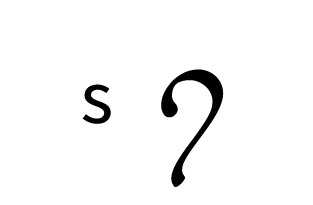 | 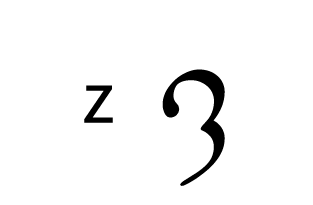 |  |
 | 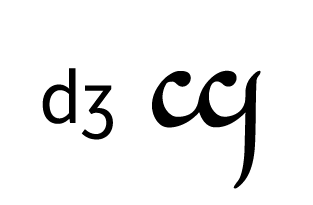 | 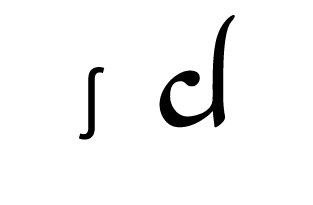 | 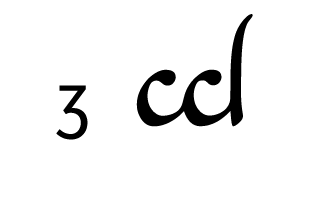 |  | 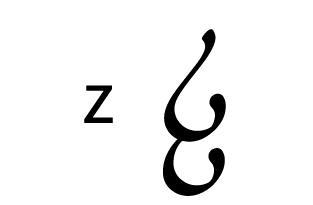 | 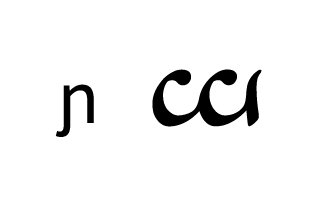 | |
| Velar |  |  | 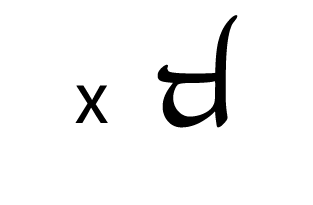 | 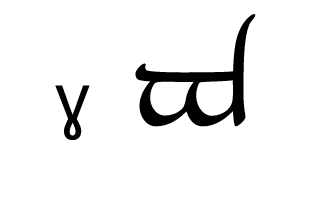 |  | ||
Place of articulation is indicated by the orientation of the curves and by horizontal strokes. Type of articulation is indicated by the height of the vertical stroke. Voicing is indicated by an additional curved stroke.
